Glossar
Bei diesem Glossar handelt es sich um eine Erweiterung meiner Notizen zur Klausurvorbereitung. Es ist sehr wahrscheinlich, dass verschiedenste Fehler/Ungenauigkeiten in den Definitionen vorkommen. Diese kann man gerne als Issue hier melden, oder man erstellt einen neuen Pull-Request.
| Begriff | Definition | Vorteile | Nachteile | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adressierungsarten |
|
||||||||||||
| ASIC | Application Specific Integrated Circuit Eine spezialisierte VLSI für einen bestimmten Zweck |
|
|
||||||||||
| Befehlszyklus |
|
||||||||||||
| Behavioral Programming (HDL) | Ähnlich sequentieller Programme. Beschreibt das Verhalten von Schaltungen. Höchste Abstraktionsebene. |
|
|
||||||||||
| Benutzermodus |
|
||||||||||||
| Big-Endian | Höchstes Byte wird an niedrigster Adresse gespeichert.
Beispiel0x01234567 wird folgend abgespeichert:
|
||||||||||||
| Block Devices |
|
||||||||||||
| Branch Prediction | Vorhersage, ob Sprung genommen wird Bei inkorrekter Vorhersage muss Pipeline neu aufgesetzt werden -> teuer | ||||||||||||
| Cache Directory Protokolle | Zentrales Verzeichnis, welches übersicht von Kopien in Caches hat. Heutiger Standard, kein Snooping mehr. | ||||||||||||
| Cache Index Bits | Bestimmt die Cachezeile, in der Adresse sein kann. 32 Byte pro Cachezeile, Cache Grösse 32 KiB -> 1024 Cachezeilen -> 10 bit Index Bei Cache Sets, wird das Set beschrieben | ||||||||||||
| Cache Offset Bits | Unterste Bits, bestimmen byte(?) index in einer Zeile. 32 Byte pro Cachezeile -> 5bit | ||||||||||||
| Cache Snooping | Gemeinsamer Bus zwischen Caches, alle Teilnehmer hören mit.
|
|
|
||||||||||
| Cache Tag Bit | Oberste Bits, beschreiben welche Daten in Cachezeile sind | ||||||||||||
| Capacity Cache Misses | Der Speicherblock wäre auch verdrängt worden, wenn der Cache vollassoziativ wäre. | ||||||||||||
| CISC | Complex Instruction Set Computer Befehlssatz mit vielen Instruktionen, steht im Gegensatz zu RISC. Wird durch Mikroprogramme realisiert. |
|
|
||||||||||
| CMOS |

Complementary metal-oxide semiconductor Besteht aus NPN und PNP Transistor. In der Abbildung ist ein CMOS Inverter zu sehen. Abaddon1337, CC BY-SA 3.0, via Wikimedia Commons |
|
|||||||||||
| Compulsory (cold) Cache Misses | Erster Zugriff auf eine Adresse, nicht zu vermeiden | ||||||||||||
| Conflict Cache Misses | Speicherblock wurde verdrängt, da ein andere Block auf das gleiche Cache Set abgebildet wurde. |
|
|||||||||||
| CPLD | Complex programmable logic device Ein CPLD besteht aus mehreren SPLD Arrays welche programmierbar miteinander verbunden sind. | ||||||||||||
| Dataflow Programming (HDL) | Boolesche Gleichungen, hierbei werden Automaten (Übergangsdiagramme) implementiert. Liegt zwischen Behavioral und Structural. | ||||||||||||
| Decoder |
n Eingänge zu 2n einzigartigen Ausgängen. Nur ein Ausgang wird dabei auf 1 gesetzt. 
Ein 2 zu 4 Bit Decoder |
||||||||||||
| Dennard Scaling | Besagt, dass mit kleineren Transistoren auch die nötige Stromleistung zurück geht. Endete ca 2005, da Prozessoren nicht mehr mehr Leistung benötigen, man setzt auf mehrere Kerne. | ||||||||||||
| Direct I/O |
|
|
|
||||||||||
| Direct Mapped Cache | Jede Adresse passt zu einer Cachezeile, die Index-Bits bestimmen die Lage der Daten im Cache. |
|
|
||||||||||
| DMA | Direct Memory Access
|
||||||||||||
| DRAM | Dynamic Random Access Memory
Kondensator mit Information, hat eine Auswahlleitung und eine Bitleitung. Erfordert regelmässigen DRAM Refresh.
|
|
|
||||||||||
| Encoder |
2n Eingänge werden binär kodiert auf n Ausgänge, so lange nur ein Eingang an ist. 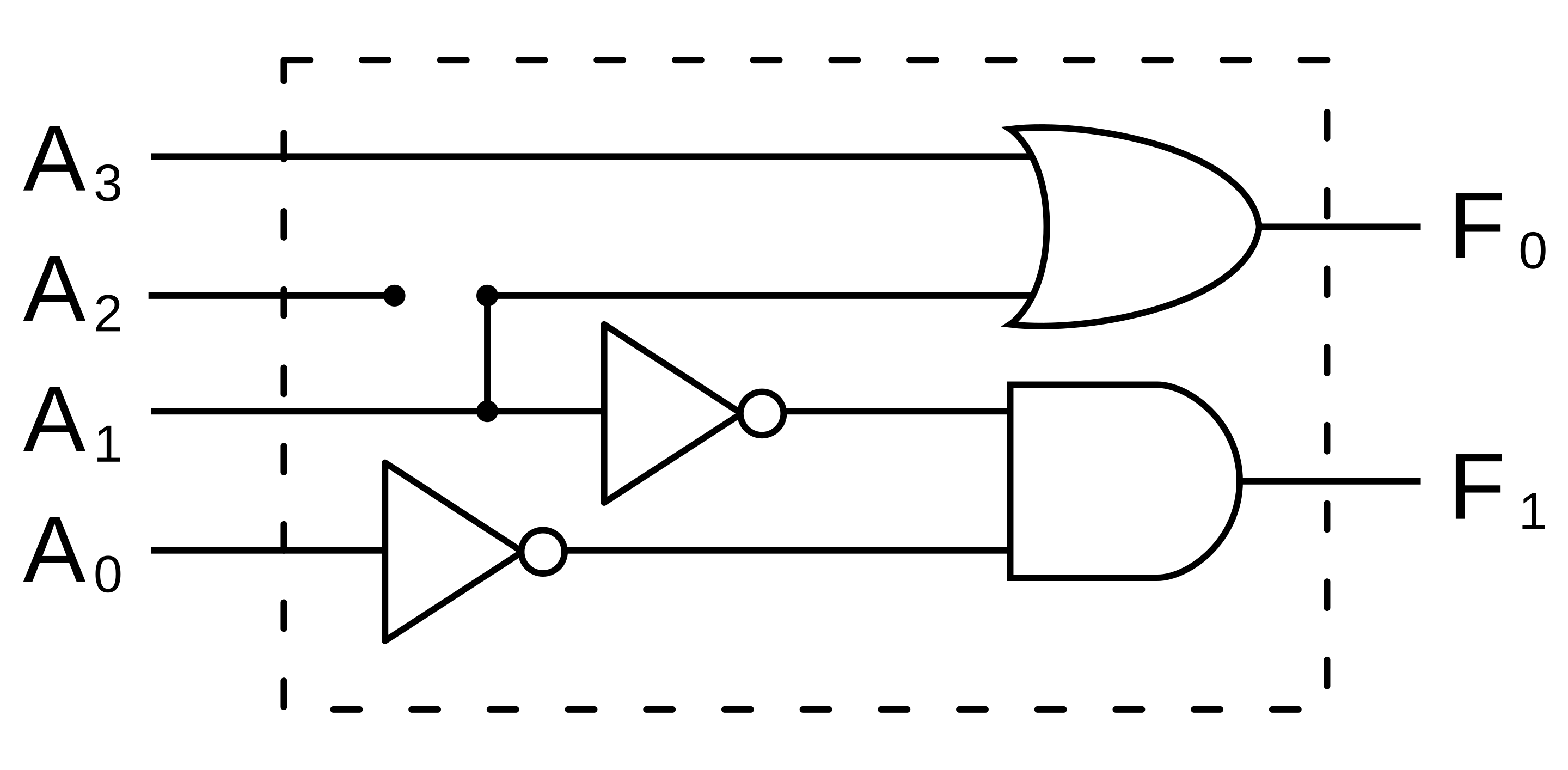
Ein 4 zu 2 Bit Decoder |
||||||||||||
| Ethernet | Am weitesten verbreitete Familie von Netztechnologien
|
||||||||||||
| Exceptions |
|
||||||||||||
| Exklusiver Cache | Jeder Speicherblock existiert nur einmal in der gesamnten Cachehierarchie. Häufig bei AMD verwendet. | ||||||||||||
| FPGA | Field Programmable Gate Array
|
||||||||||||
| GPU | Eine Graphics Processing Unit ist eine VLSI welcher auf extremes SIMD setzt. |
|
|
||||||||||
| Gründe für Moduswechsel |
|
||||||||||||
| Hardware Prefetching | Hardware untersucht Zugriffsadressen -> Erkennt Muster -> Liest zukünftige Daten. Beispiel: Prefetch Folgezeile oder Strided Prefetcher | ||||||||||||
| Hardware Thread |
|
||||||||||||
| HDL | Hardware Description Language Beschreibung einzelner Komponenten für die Entwicklung von FPGAs | ||||||||||||
| Inklusiver Cache | Alle Speicherblöcke sind auch in dem nächst grösseren Cache enthalten. Häufig bei Intel verwendet. | ||||||||||||
| Interrupt-driven I/O | Prozessor löst Zugriff aus, E/A arbeitet alleine, Abschluss wird durch Interrupt signalisiert. Steht im Gegensatz zu Direct I/O | ||||||||||||
| Interrupts |
|
||||||||||||
| Little-Endian | Höchstes Byte steht an höchster Adresse. Wird von Intel verwendet und wird deutlich häufiger
verwendet.
Beispiel0x01234567 wird folgend abgespeichert:
|
||||||||||||
| Load/Store-Architektur | Auch Register-Register-Maschine genannt.
|
||||||||||||
| LUT | Lookup Table
Zentrales Element eines Logikblocks in einem FPGA.
|
||||||||||||
| Mealy Automat | Ein deterministischer endlicher Automat, dessen Ausgabe von seinem Zustand und seiner Eingabe abhängt. | ||||||||||||
| Mehrkern Architektur | Mehrere HW Threads in einem System
|
||||||||||||
| Memory Mapped I/O |
|
||||||||||||
| Memory Mountain |
|
||||||||||||
| Mengenassoziativer Cache |
|
||||||||||||
| MESI Protokoll | MSI, aber mit Exclusive Zustand. Exclusive: Wert in einem Cache, unverändert |
||||||||||||
| MIMD | Multiple Instruction Multiple Data
n Rechenwerke, n Leitwerke -> Parallele Systeme
|
||||||||||||
| Misaligned Data | Ein Speicherzugriff ist aligned wenn die Daten, auf welche zugegriffen wird, n Bytes lang sind und das einzelne Datum an einer Adresse liegt welche durch n teilbar ist. Bytes sind somit immer aligned. Ist die Eigenschaft nicht erfüllt, sind die Daten misaligned. |
|
|
||||||||||
| MMU | Memory management unit Separate Hardware auf der CPU, welche virtuelle Adressen via LUT in Physikalische übersetzt. | ||||||||||||
| Moore Automat | Ein endlicher Automat, dessen Ausgabe ausschließlich von seinem Zustand abhängt. | ||||||||||||
| MSI Protokoll | Jede Cachezeile muss ihren Status mitverfolgen.
|
||||||||||||
| Multiplexer | Wid genutzt um Daten auszuwählen. Es wird anhand eines Selector- Eingangs ein Eingang ausgewählt und
dieser weitergeleitet zum Ausgang.
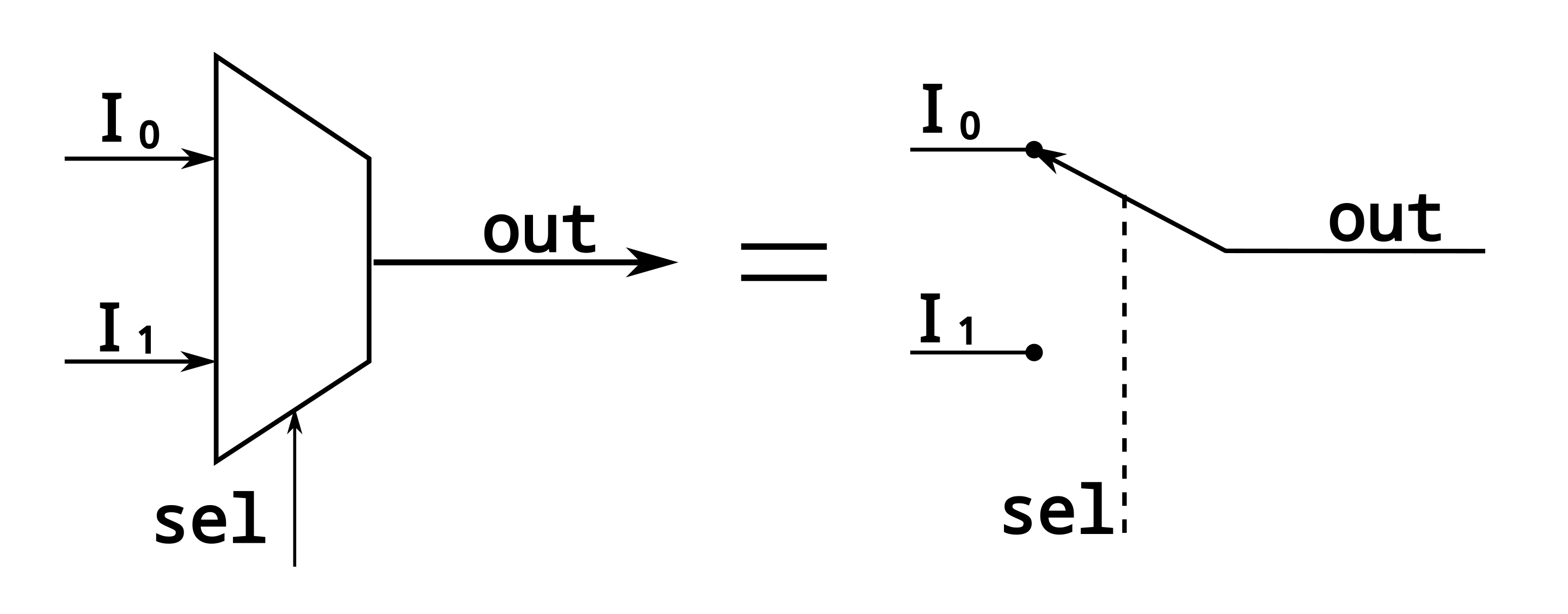
2-zu-1 Multiplexer. Entspricht einem kontrollierten Switch. |
||||||||||||
| Multithreading | Mehrere HW Threads in einem Prozessorkern.
|
||||||||||||
| NAND Flash | Bei der Verbindung zwischen der Bit-Line und dem Word-Line handet es sich um ein NAND Gate. Wird in SSDs und USB Sticks verwendet. |
|
|
||||||||||
| Nebenläufige und Parallele Programme | Nebenläufig
|
||||||||||||
| NIC | Network Interface Card Komponente im Computer die den Computer mit einem Netzwerk verbindet. | ||||||||||||
| Non-uniform Memory Access |
|
|
|
||||||||||
| NOR Flash | Bei der Verbindung zwischen der Bit-Line und dem Word-Line handet es sich um ein NOR Gate. Gut für BIOS und andere Boot Medien. |
|
|||||||||||
| NPN Transistor | NPN ist ein Arbeitskontakt -> Leitend, falls Strom anliegt | ||||||||||||
| Out-of-Order Execution | Auch dynamisches Scheduling genannt. Unabhängige Instruktionen können ausgeführt werden, obwohl vorherige Operationen blockiert sind, trotzdem transparent |
|
|
||||||||||
| PAL / GAL | Programmable/General Array Logic UND programmierbar, ODER fest
|
||||||||||||
| Physically Indexed Cache | Cache nach MMU, Cache arbeitet mit physikalischen Adressen |
|
|
||||||||||
| Pipeline Control Hazard | Verursacht durch Sprünge, da Befehl unbekannt | ||||||||||||
| Pipeline Data Hazard | Datenabhängigkeiten nicht erfüllt | ||||||||||||
| Pipeline Structural Hazard | Ressourcenprobleme in der Hardware | ||||||||||||
| Pipelining | Bearbeitung eines Objekts wird in Teilschritte zerlegt und sequentiell ausgeführt. Die Phasen werden
für verschiedene Objekte überlappend abgearbeitet. Kann sowohl in Software als auch in Hardware umgesetzt werden. |
||||||||||||
| PLA | Programmable Logic Array Für DNFs, UND gefolgt von ODER, beides programmierbar. | ||||||||||||
| PLD | Programmable Logic DeviceAllgemeiner Begriff der alle programmierbaren Schaltungen beschreibt wie SPLDs, CPLDs, und FPGAs. |
|
|
||||||||||
| PROM | Programmable Read-Only Memory UND fest, ODER programmierbar.
EPROM -> Erasable PROM, mit UV Licht EEPROM -> Electrcially EPROM |
||||||||||||
| RISC | Reduced Instruction Set Computer. Hoch optimierter, minimalistischer Befehlssatz mit nur wenig unterschiedlichen Instruktionen. Steht im Gegensatz zu CISC. Wird durch feste Verdrahtung realisiert. |
|
|
||||||||||
| ROM | Read Only Memory UND fest, ODER fest, dementsprechend nicht programmierbar. | ||||||||||||
| SIMD | Single Instruction Multiple Data n Rechenwerke, 1 Leitwerk
-> Pipelines, Vectors, GPUs (Moderne GPUs sind MIMD, mehrere extreme SIMD Blöcke) Mehrere Daten werden durch einen Maschinenbefehl geleitet. |
||||||||||||
| Simultaneous Multithreading (SMT) | Gleichzeitige Nutzung von Ressourcen, passt zu OoO und Superskalarität. | ||||||||||||
| SISD | Single Instruction Single Data 1 Rechenwerk, 1 Leitwerk -> Seq. Verarbeitung von Neumann |
||||||||||||
| Software Prefetching | Explizite Instruktionen welche Daten in den Cache laden. |
|
|
||||||||||
| Spin-Locks | Busy waiting -> Siehe EIDI | ||||||||||||
| SPLD | Simple Programmable Logic Device Schaltnetz aus einem UND und einem ODER Array. Beide evtl. programmierbar | ||||||||||||
| SRAM | Static Random Access Memory Nutzung in Register & Caches Prinzip ähnlich zu Latch. Schreiben: Bit auf 1, Nicht Bit auf 0, Select auf 1, Inverter pegeln sich ein Lesen: Bit auf 1, Nicht Bit auf 1, Inverter ziehen somit einen Ausgang auf 0, Spannungsabfall wird gemessen |
|
|
||||||||||
| Stream Devices |
|
||||||||||||
| Structural Programming (VHDL) | Verbundenen einzelne Komponenten, beschreibt einzelene Schaultungen welche hierarchisch Verbunden werden. |
|
|
||||||||||
| Superskalarprinzip | Ein superskalarer Prozessor verfügt im Vergleich zu einem Prozessor mit sequentieller Pipeline über die n-fache Anzahl von Funktionseinheiten, Datenpfaden, Dekodierern, etc. -> n Befehle können gleichzeitig ausfgeführt werden. | ||||||||||||
| Systemmodus |
|
||||||||||||
| TLB | Translation Lookaside Buffer Kleiner Cache mit Page Table Einträgen in der MMU um Addreessübersetzung zu beschleunigen | ||||||||||||
| Uniform Memory Access (UMA) |
|
||||||||||||
| Virtually Indexed Cache | Cache vor MMU, Cache arbeitet also mit virtuellen Adressen. |
|
Mehrere Prozesse verwenden die gleichen virtuellen Adressen. Lösungen:
|
||||||||||
| VLIW | Very Long Instruction Word Mehrere Instruktionen in einem Befehl, spezielle Prozessoren. |
|
|
||||||||||
| VLSI | Very-large-scale Integration ist eine Herstellungstechnologie bei der viele Tausende Transistoren in einen einzelnen Chip integriert werden. | ||||||||||||
| Volatile | Erneut Programmierbar | ||||||||||||
| Voll assoziativer Cache | Jede Adresse kann auf jede Cache Zeile abgebildet werden, es existiert nur ein "Cache Set". |
|
|
||||||||||
| Von-Neumann Architekturkonzept |
|
||||||||||||
| Yielding Locks | Falls Lock vergeben, gebe Thread ab |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Vergleiche
| Begriff | Vergleich | Gemeinsamkeiten |
|---|---|---|
FPGA
|
ASIC
|
|
FPGA
|
CPU
|
|
Pipelining
|
Superskalar
|
Beide erlauben Parallelität, ergänzen sich |
Thread
|
Prozesse
|